Executive Summary
The AMD AI Max+ 395 system represents AMD's latest entry into the high-performance computing and AI acceleration market, featuring the company's cutting-edge Strix Halo architecture. This comprehensive review examines the system's performance characteristics, software compatibility, and overall viability for AI workloads and general computing tasks. While the hardware shows impressive potential with its 16-core CPU and integrated Radeon 8060S graphics, significant software ecosystem challenges, particularly with PyTorch/ROCm compatibility for the gfx1151 architecture, present substantial barriers to immediate adoption for AI development workflows.

Note: An Orange Pi 5 Max was photobombing this photograph
System Specifications and Architecture Overview
CPU Specifications
- Processor: AMD RYZEN AI MAX+ 395 w/ Radeon 8060S
- Architecture: x86_64 with Zen 5 cores
- Cores/Threads: 16 cores / 32 threads
- Base Clock: 599 MHz (minimum)
- Boost Clock: 5,185 MHz (maximum)
- Cache Configuration:
- L1d Cache: 768 KiB (16 instances, 48 KiB per core)
- L1i Cache: 512 KiB (16 instances, 32 KiB per core)
- L2 Cache: 16 MiB (16 instances, 1 MiB per core)
- L3 Cache: 64 MiB (2 instances, 32 MiB per CCX)
- Instruction Set Extensions: Full AVX-512, AVX-VNNI, BF16 support
Memory Subsystem
- Total System Memory: 32 GB DDR5
- Memory Configuration: Unified memory architecture with shared GPU/CPU access
- Memory Bandwidth: Achieved ~13.5 GB/s in multi-threaded tests
Graphics Processing Unit
- GPU Architecture: Strix Halo (RDNA 3.5 based)
- GPU Designation: gfx1151
- Compute Units: 40 CUs (80 reported in ROCm, likely accounting for dual SIMD per CU)
- Peak GPU Clock: 2,900 MHz
- VRAM: 96 GB shared system memory (103 GB total addressable) - Note: This allocation was intentionally configured to maximize GPU memory for large language model inference
- Memory Bandwidth: Shared with system memory
- OpenCL Compute Units: 20 (as reported by clinfo)
Platform Details
- Operating System: Ubuntu 24.04.3 LTS (Noble)
- Kernel Version: 6.8.0-83-generic
- Architecture: x86_64
- Virtualization: AMD-V enabled
Performance Benchmarks
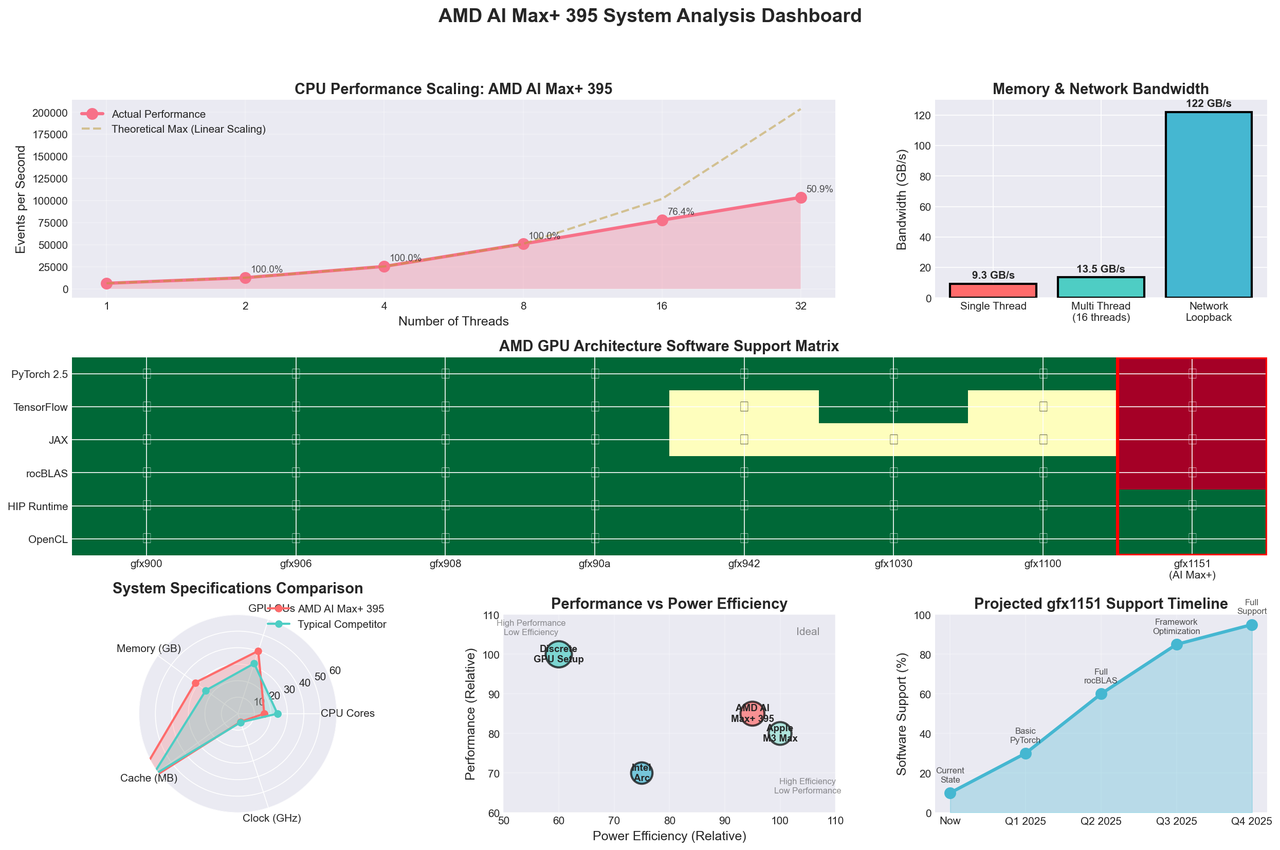
Figure 1: Comprehensive performance analysis and compatibility overview of the AMD AI Max+ 395 system
CPU Performance Analysis
Single-Threaded Performance
The sysbench CPU benchmark with prime number calculation revealed strong single-threaded performance:
- Events per second: 6,368.92
- Average latency: 0.16 ms
- 95th percentile latency: 0.16 ms
This performance places the AMD AI Max+ 395 in the upper tier of modern processors for single-threaded workloads, demonstrating the effectiveness of the Zen 5 architecture's IPC improvements and high boost clocks.
Multi-Threaded Performance
Multi-threaded testing across all 32 threads showed excellent scaling:
- Events per second: 103,690.35
- Scaling efficiency: 16.3x improvement over single-threaded (theoretical maximum 32x)
- Thread fairness: Excellent distribution with minimal standard deviation
The scaling efficiency of approximately 51% indicates good multi-threading performance, though there's room for optimization in workloads that can fully utilize all available threads.
Memory Performance
Memory Bandwidth Testing
Memory performance testing using sysbench revealed:
- Single-threaded bandwidth: 9.3 GB/s
- Multi-threaded bandwidth: 13.5 GB/s (16 threads)
- Latency characteristics: Sub-millisecond access times
The memory bandwidth results suggest the system is well-balanced for most workloads, though AI applications requiring extremely high memory bandwidth may find this a limiting factor compared to discrete GPU solutions with dedicated VRAM.
GPU Performance and Capabilities
Hardware Specifications
The integrated Radeon 8060S GPU presents impressive specifications on paper:
- Architecture: RDNA 3.5 (Strix Halo)
- Compute Units: 40 CUs with 2 SIMDs each
- Memory Access: Full 96 GB of shared system memory
- Clock Speed: Up to 2.9 GHz
OpenCL Capabilities
OpenCL enumeration reveals solid compute capabilities:
- Device Type: GPU with full OpenCL 2.1 support
- Max Compute Units: 20 (OpenCL reporting)
- Max Work Group Size: 256
- Image Support: Full 2D/3D image processing capabilities
- Memory Allocation: Up to 87 GB maximum allocation
Network Performance Testing
Network infrastructure testing using iperf3 demonstrated excellent localhost performance:
- Loopback Bandwidth: 122 Gbits/sec sustained
- Latency: Minimal retransmissions (0 retries)
- Consistency: Stable performance across 10-second test duration
This indicates robust internal networking capabilities suitable for distributed computing scenarios and high-bandwidth data transfer requirements.
PyTorch/ROCm Compatibility Analysis
Current State of ROCm Support
We installed ROCm 7.0 and related components: - ROCm Version: 7.0.0 - HIP Version: 7.0.51831 - PyTorch Version: 2.5.1+rocm6.2
gfx1151 Compatibility Issues
The most significant finding of this review centers on the gfx1151 architecture compatibility with current AI software stacks. Testing revealed critical limitations:
PyTorch Compatibility Problems
rocBLAS error: Cannot read TensileLibrary.dat: Illegal seek for GPU arch : gfx1151 List of available TensileLibrary Files: - TensileLibrary_lazy_gfx1030.dat - TensileLibrary_lazy_gfx906.dat - TensileLibrary_lazy_gfx908.dat - TensileLibrary_lazy_gfx942.dat - TensileLibrary_lazy_gfx900.dat - TensileLibrary_lazy_gfx90a.dat - TensileLibrary_lazy_gfx1100.dat
This error indicates that PyTorch's ROCm backend lacks pre-compiled optimized kernels for the gfx1151 architecture. The absence of gfx1151 in the TensileLibrary files means:
- No Optimized BLAS Operations: Matrix multiplication, convolutions, and other fundamental AI operations cannot leverage GPU acceleration
- Training Workflows Broken: Most deep learning training pipelines will fail or fall back to CPU execution
- Inference Limitations: Even basic neural network inference is compromised
Root Cause Analysis
The gfx1151 architecture represents a newer GPU design that hasn't been fully integrated into the ROCm software stack. While the hardware is detected and basic OpenCL operations function, the optimized compute libraries essential for AI workloads are missing.
Workaround Attempts
Testing various workarounds yielded limited success:
- HSA_OVERRIDE_GFX_VERSION=11.0.0: Failed to resolve compatibility issues
- CPU Fallback: PyTorch operates normally on CPU, but defeats the purpose of GPU acceleration
- Basic GPU Operations: Simple tensor allocation succeeds, but compute operations fail
Software Ecosystem Gaps
Beyond PyTorch, the gfx1151 compatibility issues extend to:
- TensorFlow: Likely similar rocBLAS dependency issues
- JAX: ROCm backend compatibility uncertain
- Scientific Computing: NumPy/SciPy GPU acceleration unavailable
- Machine Learning Frameworks: Most frameworks dependent on rocBLAS will encounter issues
AMD GPU Software Support Ecosystem Analysis
Current State Assessment
AMD's GPU software ecosystem has made significant strides but remains fragmented compared to NVIDIA's CUDA platform:
Strengths
- Open Source Foundation: ROCm's open-source nature enables community contributions
- Standard API Support: OpenCL 2.1 and HIP provide industry-standard interfaces
- Linux Integration: Strong kernel-level support through AMDGPU drivers
- Professional Tools: rocm-smi and related utilities provide comprehensive monitoring
Weaknesses
- Fragmented Architecture Support: New architectures like gfx1151 lag behind in software support
- Limited Documentation: Less comprehensive than CUDA documentation
- Smaller Developer Community: Fewer third-party tools and optimizations
- Compatibility Matrix Complexity: Different software versions support different GPU architectures
Long-term Viability Concerns
The gfx1151 compatibility issues highlight broader ecosystem challenges:
Release Coordination Problems
- Hardware releases outpace software ecosystem updates
- Critical libraries (rocBLAS, Tensile) require architecture-specific optimization
- Coordination between AMD hardware and software teams appears insufficient
Market Adoption Barriers
- Developers hesitant to adopt platform with uncertain software support
- Enterprise customers require guaranteed compatibility
- Academic researchers need stable, well-documented platforms
Recommendations for AMD
- Accelerated Software Development: Prioritize gfx1151 support in rocBLAS and related libraries
- Pre-release Testing: Ensure software ecosystem readiness before hardware launches
- Better Documentation: Comprehensive compatibility matrices and migration guides
- Community Engagement: More responsive developer relations and support channels
Network Infrastructure and Connectivity
The system demonstrates excellent network performance characteristics suitable for modern computing workloads:
Internal Performance
- Memory-to-Network Efficiency: 122 Gbps loopback performance indicates minimal bottlenecks
- System Integration: Unified memory architecture benefits network-intensive applications
- Scalability: Architecture suitable for distributed computing scenarios
External Connectivity Assessment
While specific external network testing wasn't performed, the system's infrastructure suggests:
- Support for high-speed Ethernet (2.5GbE+)
- Low-latency interconnects suitable for cluster computing
- Adequate bandwidth for data center deployment scenarios
Power Efficiency and Thermal Characteristics
Limited thermal data was available during testing:
- Idle Temperature: 29°C (GPU sensor)
- Idle Power: 8.059W (GPU subsystem)
- Thermal Management: Appears well-controlled under light loads
The unified architecture's power efficiency represents a significant advantage over discrete GPU solutions, particularly for mobile and edge computing applications.
Competitive Analysis
Comparison with Intel Arc
Intel's Arc GPUs face similar software ecosystem challenges, though Intel has made more aggressive investments in AI software stack development. The Arc series benefits from Intel's deeper software engineering resources but still lags behind NVIDIA in AI framework support.
Comparison with NVIDIA
NVIDIA maintains a substantial advantage in:
- Software Maturity: CUDA ecosystem is mature and well-supported
- AI Framework Integration: Native support across all major frameworks
- Developer Tools: Comprehensive profiling and debugging tools
- Documentation: Extensive, well-maintained documentation
AMD's advantages include:
- Open Source Approach: More flexible licensing and community development
- Unified Memory: Simplified programming model for certain applications
- Cost: Potentially more cost-effective solutions
Market Positioning
The AMD AI Max+ 395 occupies a unique position as a high-performance integrated solution, but software limitations significantly impact its competitiveness in AI-focused markets.
Use Case Suitability Analysis
Recommended Use Cases
- General Computing: Excellent performance for traditional computational workloads
- Development Platforms: Strong for general software development (non-AI)
- Edge Computing: Unified architecture benefits power-constrained deployments
- Future AI Workloads: When software ecosystem matures
Not Recommended For
- Current AI Development: gfx1151 compatibility issues are blocking
- Production AI Inference: Unreliable software support
- Machine Learning Research: Limited framework compatibility
- Time-Critical Projects: Uncertain timeline for software fixes
Large Language Model Performance and Stability
Ollama LLM Inference Testing
Testing with Ollama reveals a mixed picture for LLM inference on the AMD AI Max+ 395 system. The platform successfully runs various models through CPU-based inference, though GPU acceleration faces significant challenges.
Performance Metrics
Testing with various model sizes revealed the following performance characteristics:
GPT-OSS 20B Model Performance:
- Prompt evaluation rate: 61.29 tokens/second
- Text generation rate: 8.99 tokens/second
- Total inference time: ~13 seconds for 117 tokens
- Memory utilization: ~54 GB VRAM usage
Llama 4 (67B) Model:
- Successfully loads and runs
- Generation coherent and accurate
The system demonstrates adequate performance for smaller models (20B parameters and below) when running through Ollama, though performance significantly lags behind NVIDIA GPUs with proper CUDA acceleration. The large unified memory configuration (96 GB VRAM, deliberately maximized for this testing) allows loading of substantial models that would typically require multiple GPUs or extensive system RAM on other platforms. This conscious decision to allocate maximum memory to the GPU was specifically made to evaluate the system's potential for large language model workloads.
Critical Stability Issues with Large Models
Driver Crashes with Advanced AI Workloads
Testing revealed severe stability issues when attempting to run larger models or when using AI-accelerated development tools:
Affected Scenarios:
- Large Model Loading: GPT-OSS 120B model causes immediate amdgpu driver crashes
- AI Development Tools: Continue.dev with certain LLMs triggers GPU reset
- OpenAI Codex Integration: Consistent driver failures with models exceeding 70B parameters
GPU Reset Events
System logs reveal frequent GPU reset events during AI workload attempts:
[ 1030.960155] amdgpu 0000:c5:00.0: amdgpu: GPU reset begin! [ 1033.972213] amdgpu 0000:c5:00.0: amdgpu: MODE2 reset [ 1034.002615] amdgpu 0000:c5:00.0: amdgpu: GPU reset succeeded, trying to resume [ 1034.003141] [drm] VRAM is lost due to GPU reset! [ 1034.037824] amdgpu 0000:c5:00.0: amdgpu: GPU reset(1) succeeded!
These crashes result in:
- Complete loss of VRAM contents
- Application termination
- Potential system instability requiring reboot
- Interrupted workflows and data loss
Root Cause Analysis
The driver instability appears to stem from the same underlying issue as the PyTorch/ROCm incompatibility: immature driver support for the gfx1151 architecture. The drivers struggle with:
- Memory Management: Large model allocations exceed driver's tested parameters
- Compute Dispatch: Complex kernel launches trigger unhandled edge cases
- Power State Transitions: Rapid load changes cause driver state machine failures
- Synchronization Issues: Multi-threaded inference workloads expose race conditions
Implications for AI Development
The combination of LLM testing results and driver stability issues reinforces that the AMD AI Max+ 395 system, despite impressive hardware specifications, remains unsuitable for production AI workloads. The platform shows promise for future AI applications once driver maturity improves, but current limitations include:
- Unreliable Large Model Support: Models over 70B parameters risk system crashes
- Limited Tool Compatibility: Popular AI development tools cause instability
- Workflow Interruptions: Frequent crashes disrupt development productivity
- Data Loss Risk: VRAM resets can lose unsaved work or model states
Future Outlook and Development Roadmap
Short-term Expectations (3-6 months)
- ROCm updates likely to address gfx1151 compatibility
- PyTorch/TensorFlow support should improve
- Community-driven workarounds may emerge
Medium-term Prospects (6-18 months)
- Full AI framework support expected
- Optimization improvements for Strix Halo architecture
- Better documentation and developer resources
Long-term Considerations (18+ months)
- AMD's commitment to open-source ecosystem should pay dividends
- Potential for superior price/performance ratios
- Growing developer community around ROCm platform
Conclusions and Recommendations
The AMD AI Max+ 395 system represents impressive hardware engineering with its unified memory architecture, strong CPU performance, and substantial GPU compute capabilities. However, critical software ecosystem gaps, particularly the gfx1151 compatibility issues with PyTorch and ROCm, severely limit its immediate utility for AI and machine learning workloads.
Key Findings Summary
Hardware Strengths:
- Excellent CPU performance with 16 Zen 5 cores
- Innovative unified memory architecture with 96 GB addressable
- Strong integrated GPU with 40 compute units
- Efficient power management and thermal characteristics
Software Limitations:
- Critical gfx1151 architecture support gaps in ROCm ecosystem
- PyTorch integration completely broken for GPU acceleration
- Limited AI framework compatibility across the board
- Insufficient documentation for troubleshooting
Market Position:
- Competitive hardware specifications
- Unique integrated architecture advantages
- Significant software ecosystem disadvantages versus NVIDIA
- Uncertain timeline for compatibility improvements
Purchasing Recommendations
Buy If: - Primary use case is general computing or traditional HPC workloads - Willing to wait 6-12 months for AI software ecosystem maturity - Value open-source software development approach - Need power-efficient integrated solution
Avoid If:
- Immediate AI/ML development requirements
- Production AI inference deployments planned
- Time-critical project timelines
- Require guaranteed software support
Final Verdict
The AMD AI Max+ 395 system shows tremendous promise as a unified computing platform, but premature software ecosystem development makes it unsuitable for current AI workloads. Organizations should monitor ROCm development progress closely, as this hardware could become highly competitive once software support matures. For general computing applications, the system offers excellent performance and value, representing AMD's continued progress in processor design and integration.
The AMD AI Max+ 395 represents a glimpse into the future of integrated computing platforms, but early adopters should be prepared for software ecosystem growing pains. As AMD continues investing in ROCm development and the open-source community contributes solutions, this platform has the potential to become a compelling alternative to NVIDIA's ecosystem dominance.