There's a moment early in any OS project where the serial port prints its first character and you realize that nothing you've written has a safety net. No libc. No kernel underneath. No syscall to fall back on. If the byte appears on the terminal, it's because you programmed the UART divisor latch, polled the line status register, and wrote to the data port. If it doesn't appear, you stare at register dumps until you find the mistake. There's no debugger; you haven't written one yet.
The closest thing I can compare it to is the first time I got a RetroShield Z80 talking over serial, that moment where a processor you wired up yourself pushes a character out of an emulated ACIA and it appears on your screen. The Z80 version involves physical hardware and solder. The x86 version is virtual (QEMU, a cross-compiler, and a Multiboot header), but the feeling is the same. You built the entire path from CPU to character. Nothing was given to you.
JokelaOS started there: a Multiboot header, a stack, and a call kmain. Everything that followed (GDT (Global Descriptor Table), IDT (Interrupt Descriptor Table), memory management, a network stack, preemptive multitasking, paging, user mode, a shell) was built one subsystem at a time, tested after every change, with no external code. No forks of existing kernels. No libc.
To be clear about what this is: JokelaOS is a toy. It's a learning project. The memory allocator is a linear scan. The scheduler has no concept of priority. The file system can't delete files. The user authentication stores passwords in plaintext in a static array. Nothing here is production-grade, and none of it is intended to be. The value is in the building: understanding what each subsystem actually does by writing it from scratch, making the mistakes, and fixing them with nothing between you and the hardware.
This is the story of what it takes to go from twenty lines of NASM to a kernel that boots, manages memory, runs user programs in Ring 3, handles syscalls, responds to pings, and gives you a command prompt.
The Target
JokelaOS targets 32-bit x86 (i686) and runs under QEMU. The toolchain is a cross-compiler (i686-elf-gcc, i686-elf-ld) with NASM for the assembly files. The C standard is gnu11; GNU extensions are required for inline assembly. There are no external libraries whatsoever, not even a freestanding string.h. Every memcpy, every memset, every printf-like function is written from scratch.
The only console is the serial port. COM1 at 0x3F8, 115200 baud, 8N1 (8 data bits, no parity, 1 stop bit). All kernel output goes through serial_printf(). This is a deliberate choice: serial is simpler than VGA text mode, works perfectly with QEMU's -serial stdio, and means the kernel's output appears directly in the host terminal. No framebuffer driver needed, no font rendering, no cursor management. Just bytes on a wire.
$ make run qemu-system-i386 -kernel build/jokelaos.bin -serial stdio \ -display none -device rtl8139,netdev=net0 \ -netdev user,id=net0 -no-reboot
Kernel Architecture
JokelaOS is monolithic: everything runs in Ring 0, in one address space. When the network stack needs a page, it calls pmm_alloc_frame() directly. When the shell loads a program, the call chain goes through the loader, the PMM, and the paging subsystem without ever crossing an address space boundary. The trade-off is that a bug in the RTL8139 driver can corrupt the process table, and a buffer overrun in the serial handler can overwrite page tables. In a toy kernel written by one person, bugs are spectacular.
A microkernel would isolate those failures, but it would also triple the code before you could print a single character. You'd need working IPC before the serial driver could talk to anything. JokelaOS is monolithic because it's the simplest architecture to build and the easiest to debug: serial_printf() anywhere can see everything.
Booting: The First 33 Lines
The entire boot sequence fits in boot.asm. Multiboot v1 requires a magic number (0x1BADB002), flags, and a checksum in a specific header format. GRUB or QEMU's -kernel loader scans for this header, loads the binary, and jumps to _start in protected mode with paging disabled.
section .multiboot align 4 dd 0x1BADB002 ; Multiboot magic dd 0x00000003 ; Flags: page-align + memory map dd -(0x1BADB002 + 0x00000003) ; Checksum section .text global _start extern kmain _start: mov esp, stack_top push 0 popf ; Clear EFLAGS push ebx ; Multiboot info struct pointer push eax ; Multiboot magic number call kmain cli .hang: hlt jmp .hang
That's it. Set up a stack, clear the flags register, push the two values the Multiboot spec guarantees (magic number in EAX, info struct pointer in EBX), and call C. If kmain ever returns, disable interrupts and halt forever.
The 16 KB stack is allocated in the BSS section, zeroed at load time. The linker script places the kernel at 1 MB (the standard x86 protected-mode load address), with .multiboot first so the bootloader can find the header within the first 8 KB of the binary.
Protection Rings: Hardware-Enforced Privilege
x86 protected mode provides four privilege levels, numbered 0 through 3, called rings. Ring 0 is the most privileged: the kernel runs here. Ring 3 is the least privileged: user programs run here. Rings 1 and 2 exist in the hardware but almost nobody uses them. Linux doesn't. Windows doesn't. JokelaOS doesn't. The practical x86 privilege model is two rings: kernel and user.
The ring system isn't a software convention. It's enforced by the CPU itself, in silicon. The processor tracks the Current Privilege Level (CPL), the ring the currently executing code belongs to, and checks it against every sensitive operation. A Ring 3 process that executes cli (disable interrupts), hlt (halt the CPU), lgdt (load a new GDT), or mov cr3 (change the page directory) triggers a General Protection Fault. The CPU literally refuses to execute the instruction. A Ring 3 process can't touch I/O ports unless the kernel has explicitly granted access through the I/O Permission Bitmap in the TSS. It can't modify its own segment registers to escalate privilege, because the CPU validates every segment load against the descriptor's DPL (Descriptor Privilege Level).
The only way for Ring 3 code to enter Ring 0 is through a gate: an interrupt gate, a trap gate, or a call gate. Gates are entries in the IDT or GDT that the kernel sets up in advance. They define the exact entry points where Ring 3 code can cross into Ring 0, what the new code and stack segments will be, and what privilege level is required to use them. There's no way for user code to jump to an arbitrary kernel address. It can only enter the kernel through the doors the kernel has built.
This is what makes an operating system an operating system rather than a library. Without ring separation, a buggy user program can corrupt kernel memory, disable interrupts, reprogram the PIC, or overwrite the page tables. With ring separation, the worst it can do is crash itself.
The mechanism that implements all of this is the Global Descriptor Table.
The GDT: Defining the World
The GDT defines memory segments: their base addresses, sizes, privilege levels, and whether they hold code or data. Each segment descriptor is an 8-byte structure with fields packed into non-obvious bit positions (a consequence of backward compatibility with the 286, which had a different descriptor format that the 386 had to extend without breaking).
JokelaOS uses a flat memory model: every segment covers the full 4 GB address space with base 0 and limit 0xFFFFFFFF. The segmentation hardware is effectively nullified, which is what you want on modern x86 where paging handles memory protection. But the GDT is still mandatory; the CPU requires it for the ring system to function. Even with flat segments, the DPL field in each descriptor is what tells the CPU "code using this segment is Ring 0" or "code using this segment is Ring 3."
The GDT has six entries:
| Index | Selector | Purpose |
|---|---|---|
| 0 | 0x00 | Null descriptor (required by x86) |
| 1 | 0x08 | Kernel code (Ring 0, execute/read) |
| 2 | 0x10 | Kernel data (Ring 0, read/write) |
| 3 | 0x18 | User code (Ring 3, execute/read) |
| 4 | 0x20 | User data (Ring 3, read/write) |
| 5 | 0x28 | Task State Segment |
Entries 1 and 2 are identical to entries 3 and 4 in every way except the DPL field: two bits in the access byte that say 00 (Ring 0) versus 11 (Ring 3). That two-bit difference is the entire kernel/user boundary.
When a user process runs, the CPU's CS register is loaded with 0x1B; that's selector 0x18 (pointing to GDT entry 3, the user code segment) OR'd with RPL 3 (the bottom two bits of the selector). The data segment registers get 0x23 (GDT entry 4, user data, RPL 3). The CPU sets CPL to match, and from that point on, every instruction is checked against Ring 3 privileges. The kernel runs with CS=0x08 (GDT entry 1, RPL 0) and DS=0x10 (GDT entry 2, RPL 0).
The TSS (Task State Segment) is the bridge between rings. When the CPU takes an interrupt while running Ring 3 code, it needs to switch to a Ring 0 stack, because you can't trust the user's stack pointer to be valid, and you certainly can't run kernel interrupt handlers on a user-controlled stack. The TSS holds the Ring 0 stack pointer (esp0). Every context switch updates the TSS with the current process's kernel stack, so the CPU always knows where to land when transitioning from user mode to kernel mode.
void gdt_init(void) { gdt_set_entry(0, 0, 0, 0, 0); // Null gdt_set_entry(1, 0, 0xFFFFFFFF, 0x9A, 0xCF); // Kernel code gdt_set_entry(2, 0, 0xFFFFFFFF, 0x92, 0xCF); // Kernel data gdt_set_entry(3, 0, 0xFFFFFFFF, 0xFA, 0xCF); // User code gdt_set_entry(4, 0, 0xFFFFFFFF, 0xF2, 0xCF); // User data // TSS entry built separately ... }
The access byte 0x9A means: present, Ring 0, code segment, executable, readable. 0xFA means the same thing but Ring 3. These magic numbers come straight from the Intel manuals and they're the kind of thing you get wrong three times before you get right once.
Interrupts: Exceptions, IRQs, and the PIC
The IDT maps interrupt vectors to handler functions. JokelaOS sets up 256 entries: CPU exceptions (0-31), hardware IRQs (32-47), and the syscall gate (0x80).
The x86 PIC needs remapping. By default, the master PIC maps IRQs 0-7 to interrupt vectors 8-15, which collide with CPU exceptions (double fault is vector 8, for instance). The standard fix is to remap the master PIC to vectors 32-39 and the slave to 40-47. This requires sending four Initialization Command Words to each PIC in the correct sequence, the kind of hardware protocol that hasn't changed since the IBM PC/AT in 1984.
ISR stubs are written in NASM. Each one pushes an error code (or a dummy zero for exceptions that don't push one), pushes the interrupt number, saves all general-purpose registers, calls the C handler, restores registers, and does an iret. The stubs are generated with macros:
%macro ISR_NOERRCODE 1 global isr%1 isr%1: push dword 0 ; dummy error code push dword %1 ; interrupt number jmp isr_common %endmacro
The C-side dispatcher checks the interrupt number. For exceptions (0-31), it prints the register state and halts, since there's no recovery from a page fault when you don't have a page fault handler yet. For IRQs (32-47), it calls the registered handler function and sends an EOI command to the PIC. For interrupt 0x80, it dispatches to the syscall handler.
One critical detail: interrupt 0x80 is set as a trap gate with DPL 3, not an interrupt gate. This means Ring 3 code can trigger it with int 0x80. All other interrupt gates are DPL 0, so a user program that tries to execute int 0x00 gets a General Protection Fault instead. This is the mechanism that makes syscalls work while keeping everything else protected.
Memory: Three Allocators
JokelaOS has three layers of memory management, each built on top of the previous one.
The Bump Allocator
The simplest possible allocator. A pointer starts at the first page boundary after the kernel image (_kernel_end from the linker script) and only moves forward. kmalloc(size) aligns the pointer to 16 bytes, returns it, and advances by size. There is no kfree(). Memory allocated with the bump allocator is permanent.
This sounds primitive, and it is. But it's also exactly right for kernel initialization. The GDT, IDT, page tables, file system metadata, user table; these are allocated once and never freed. The bump allocator handles all of them with zero fragmentation and zero overhead.
The Physical Memory Manager
Once the kernel needs to allocate and free pages dynamically (for process stacks, program code, page tables), it needs a real allocator. The PMM uses a bitmap: one bit per 4 KB physical frame, supporting up to 256 MB of RAM (65,536 frames, 8 KB bitmap).
Initialization parses the Multiboot memory map to find usable RAM regions, then marks everything from frame 0 through the end of the bump heap as reserved. This protects the IVT, BIOS data area, kernel image, and all bump-allocated structures from being handed out as free pages.
uint32_t pmm_alloc_frame(void) { for (uint32_t i = 0; i < total_frames; i++) { if (!(bitmap[i / 8] & (1 << (i % 8)))) { bitmap[i / 8] |= (1 << (i % 8)); free_count--; return i * PAGE_SIZE; } } return 0; // out of memory }
Linear scan, no free lists, no buddy system. It's O(n) per allocation, which is fine when n is measured in thousands and allocations are infrequent. A production kernel would use something smarter. This kernel allocates a few dozen pages total.
Paging
With physical frames available, the kernel can enable paging. paging_init() builds a page directory and 32 page tables, identity-mapping the first 128 MB of physical memory (virtual address = physical address). The page directory goes into CR3, and setting the PG bit in CR0 turns the MMU on.
Identity mapping means the kernel doesn't need to worry about virtual-to-physical translation for its own code and data. Kernel pointers just work. When user processes need memory, the loader allocates physical frames and maps them into the process's address space with the PG_USER flag set, allowing Ring 3 access.
void paging_map_page(uint32_t virt, uint32_t phys, uint32_t flags) { uint32_t dir_idx = virt >> 22; uint32_t tbl_idx = (virt >> 12) & 0x3FF; if (!(page_directory[dir_idx] & PG_PRESENT)) { uint32_t tbl_frame = pmm_alloc_frame(); memset((void *)tbl_frame, 0, PAGE_SIZE); page_directory[dir_idx] = tbl_frame | PG_PRESENT | PG_WRITE | flags; } uint32_t *table = (uint32_t *)(page_directory[dir_idx] & 0xFFFFF000); table[tbl_idx] = (phys & 0xFFFFF000) | flags; asm volatile("invlpg (%0)" : : "r"(virt) : "memory"); }
The invlpg instruction flushes the TLB entry for the mapped virtual address, which is critical. Without it, the CPU might use a stale translation from its cache and access the wrong physical page.
The Network Stack
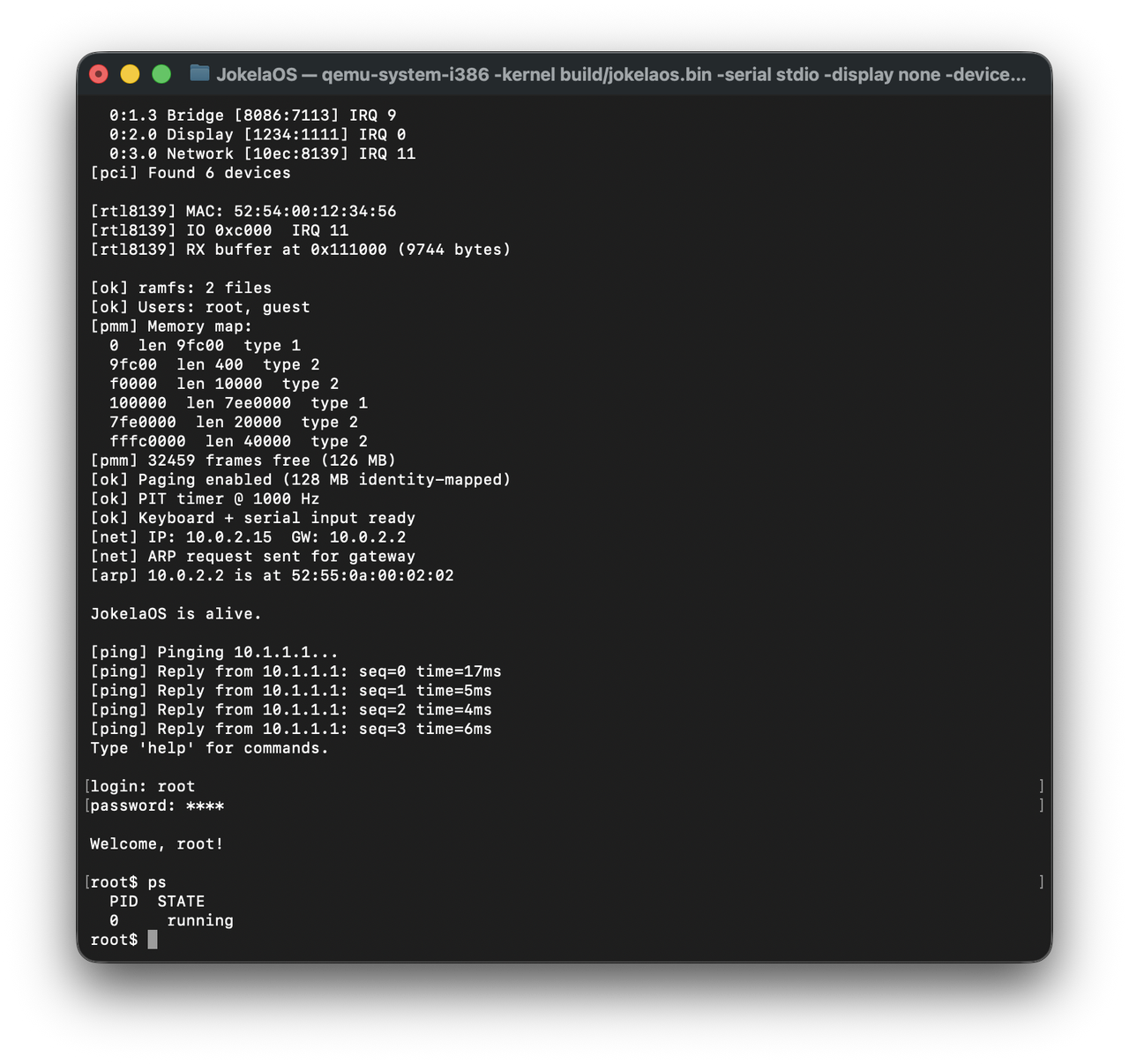
JokelaOS has a working network stack, the one subsystem where "toy" undersells it slightly. It resolves ARP, constructs IPv4 packets with correct checksums, and handles ICMP echo request/reply with measured round-trip times. There's no TCP, no UDP, no sockets. But the packets that leave this kernel are real packets that traverse real networks.
The NIC is an emulated RTL8139, the simplest PCI Ethernet controller that QEMU supports. The driver initializes the chip by writing to its configuration registers: reset, enable transmitter and receiver, set up a receive ring buffer, configure the interrupt mask, and unmask IRQ 11. Packet transmission uses a four-descriptor TX ring; reception is interrupt-driven through the RTL8139's ring buffer.
PCI enumeration scans the configuration space to find the RTL8139 by vendor/device ID (0x10EC:0x8139), reads the I/O base address from BAR0, and enables bus mastering. This is the only driver in the system; there's no USB, no disk, no display. One NIC, one network.
The stack is layered:
| Layer | Module | Purpose |
|---|---|---|
| Link | ethernet.c |
Frame demux by EtherType |
| ARP | arp.c |
Table + request/reply |
| Network | ipv4.c |
Routing, header checksum |
| Transport | icmp.c |
Echo reply + outgoing ping |
On boot, the kernel sends an ARP request for the gateway (10.0.2.2, QEMU's default) and waits for the reply. Once the gateway's MAC address is resolved, the kernel can ping arbitrary hosts through QEMU's SLIRP NAT. A ping 10.1.1.1 from the shell constructs an ICMP echo request, wraps it in an IPv4 packet, wraps that in an Ethernet frame, and pushes it out through the RTL8139's TX ring. When the reply comes back, the receive ISR fires, the Ethernet layer demuxes by EtherType, the IP layer validates the checksum, and the ICMP handler matches the echo reply to the outstanding request and computes the RTT.
root$ ping 10.1.1.1 [ping] Pinging 10.1.1.1... 64 bytes from 10.1.1.1: seq=1 time=4 ms 64 bytes from 10.1.1.1: seq=2 time=2 ms 64 bytes from 10.1.1.1: seq=3 time=3 ms 64 bytes from 10.1.1.1: seq=4 time=2 ms
Getting here required writing every byte-order conversion (htons, htonl), every checksum computation (the IP header checksum is a one's complement sum of 16-bit words), every packet layout (Ethernet header is 14 bytes, IP header is 20, ICMP is 8 plus payload). None of this is hard individually. Together, it's a thousand places to put a byte in the wrong order.
Processes and Preemptive Multitasking
The process subsystem manages up to 16 processes in a static table. Each process has a state (UNUSED, READY, RUNNING, DEAD), a kernel stack pointer, and a user-mode entry point and stack.
Process creation doesn't follow the UNIX fork()/exec() model. There's no cloning of address spaces, no copy-on-write, no replacing the current process image. Instead, the loader allocates fresh physical frames for the program's code and stack, copies the flat binary into the code pages, and calls proc_create(), which allocates a 4 KB kernel stack and builds a fake stack frame on it. This stack frame is what context_switch() will "return" into on the process's first schedule; it contains saved registers and a return address pointing to proc_entry_user().
proc_entry_user() is a small assembly sequence that performs the Ring 0 to Ring 3 transition. It sets the data segment registers to the user data selector (0x23), pushes a fake interrupt frame (SS, ESP, EFLAGS with IF=1, CS, EIP), and executes iret. The CPU pops the frame, switches to Ring 3, and starts executing the user program. From the hardware's perspective, this looks identical to returning from an interrupt that happened to interrupt a user-mode program, which is exactly the trick.
static void proc_entry_user(void) { process_t *p = proc_current(); asm volatile( "mov $0x23, %%ax \n" "mov %%ax, %%ds \n" "mov %%ax, %%es \n" "mov %%ax, %%fs \n" "mov %%ax, %%gs \n" "push $0x23 \n" // SS "push %0 \n" // ESP "pushf \n" "pop %%eax \n" "or $0x200, %%eax\n" // Set IF "push %%eax \n" // EFLAGS "push $0x1B \n" // CS (user code) "push %1 \n" // EIP "iret" : : "r"(p->user_esp), "r"(p->user_eip) : "eax", "memory" ); }
Context switching uses a simple assembly stub in switch.asm. It saves the callee-saved registers (EBP, EBX, ESI, EDI), stores ESP into the old process's slot, loads the new process's ESP, restores registers, and returns. The ret instruction pops the return address from the new stack and resumes where that process left off.
Scheduling is preemptive round-robin. The PIT fires at 1000 Hz. Every 10 ticks (10 ms), the IRQ handler calls proc_schedule(), which finds the next READY process and switches to it. If no user processes are ready, control stays with PID 0 (the kernel/shell). This is the minimum viable scheduler: no priorities, no time slices, no fairness guarantees. But it works: two user programs printing characters to serial run concurrently, interleaved by the timer.
Syscalls
User programs communicate with the kernel through int 0x80. The mechanism, a software interrupt that transitions from Ring 3 to Ring 0, is the same one Linux used on i386 before sysenter replaced it. The register convention is borrowed too: syscall number in EAX, arguments in EBX/ECX/EDX/ESI/EDI, return value in EAX. But that's where the resemblance ends.
JokelaOS is not a UNIX. The syscall numbers are custom (exit is 0, write is 1, getpid is 2, read is 3), not Linux's i386 table (where exit is 1, read is 3, write is 4, getpid is 20). There's no fork(), no exec(), no open(), no close(), no signals, no pipes. File descriptors 0 and 1 exist as concepts (stdin maps to the keyboard buffer, stdout maps to the serial port) but there's no file descriptor table behind them. The syscall handler just checks if (fd == 1) and calls serial_putchar(). The process model isn't UNIX either; there's no parent/child relationship, no wait(), no process groups. Processes are created by the loader and scheduled round-robin until they exit. It's closer to a microcontroller RTOS than to anything in the UNIX lineage.
Four syscalls are implemented:
| Number | Name | Arguments | Description |
|---|---|---|---|
| 0 | SYS_EXIT | ebx=status | Terminate process |
| 1 | SYS_WRITE | ebx=fd, ecx=buf, edx=len | Write to serial (fd=1) |
| 2 | SYS_GETPID | - | Return current PID |
| 3 | SYS_READ | ebx=fd, ecx=buf, edx=len | Read from keyboard (fd=0) |
This is enough to write programs that print output, read input, identify themselves, and exit cleanly. The syscall dispatcher validates file descriptors (only 0 and 1 are legal) and bounds-checks lengths. SYS_WRITE sends bytes to the serial port; SYS_READ drains the keyboard buffer non-blocking.
User programs are flat binaries: raw machine code with no headers, no relocations, no ELF parsing. The loader copies the binary to freshly allocated pages and jumps to byte zero. Programs that need to reference their own data use position-independent tricks:
call next ; push EIP next: pop ebp ; EBP = address of this instruction lea ecx, [ebp + offset_to_data]
This is the same technique used by shellcode and position-independent code on x86. It works because call pushes the address of the next instruction, which gives you a known reference point relative to the code's actual load address.
The Shell

With all the subsystems in place, the shell ties them together into something interactive. shell_run() is the kernel's main loop after initialization. It presents a login prompt, authenticates against the user table, and drops into a command interpreter.
============================== JokelaOS v0.1 ============================== [ok] GDT loaded (ring 0 + ring 3 + TSS) [ok] IDT loaded, PIC remapped [ok] Multiboot confirmed [ok] Multiboot info at 0x9500 [ok] Bump allocator ready PCI 00:03.0 - vendor 10EC device 8139 (RTL8139) [ok] RTL8139 ready, MAC=52:54:00:12:34:56, IRQ=11 [ok] ramfs: 2 files [ok] Users: root, guest [ok] PMM: 31269 free frames (122 MB) [ok] Paging enabled (128 MB identity-mapped) [ok] PIT timer @ 1000 Hz [ok] Keyboard + serial input ready JokelaOS is alive. login: root password: **** root$
The shell supports: help, ls, run <program>, ps, mem, ping <ip>, uptime, whoami, and logout. The line editor handles backspace. Password input echoes asterisks. The run command loads a flat binary from ramfs, creates a process, and the scheduler picks it up on the next timer tick.
ps shows the process table:
root$ ps
PID STATE
0 RUNNING
1 READY
2 DEAD
mem shows memory usage:
root$ mem Heap used: 8832 bytes PMM free: 31267 frames (122 MB)
The keyboard input path is worth noting. The PS/2 keyboard controller fires IRQ 1. The handler reads the scancode from port 0x60, converts it to ASCII using a US QWERTY lookup table (with shift modifier tracking), and drops it into a 256-byte circular buffer. Serial input takes the same path; the UART's receive interrupt (IRQ 4) reads the incoming byte and injects it into the keyboard buffer. This means the shell works identically whether you're typing on a PS/2 keyboard or through the QEMU serial console.
The RAM File System
User programs need to live somewhere. With no disk driver, the file system is purely in-memory. ramfs stores up to 32 files, each with a name (28 bytes), a data pointer, and a size. ramfs_create() allocates space with the bump allocator and copies the binary in. ramfs_find() does a linear search by name.
During boot, two test programs are embedded directly in kmain.c as byte arrays of hand-assembled x86 machine code. One prints the character '1' ten times; the other prints '2' ten times. Both use SYS_WRITE to output through the serial port and SYS_EXIT to terminate cleanly. They're loaded into ramfs, and run print1 from the shell executes them in user mode.
This is about as minimal as a file system gets. No directories, no permissions, no deletion. But it demonstrates the complete path from "bytes in kernel memory" to "user-mode process executing with its own address space."
What I Learned
The boot process is the hardest part. Not because the code is complex (boot.asm is 33 lines), but because when something goes wrong, you have zero diagnostic capability. The serial port isn't initialized yet. The IDT isn't loaded. If your Multiboot header checksum is wrong by one bit, QEMU silently fails. You're debugging with QEMU's -d int flag and reading hex dumps of interrupt frames.
x86 protected mode is an archaeology project. The PIC remapping sequence dates from the IBM PC/AT (1984). The GDT access bytes encode information in bit patterns designed for hardware that predates flat memory models. The TSS exists because Intel's original vision for the 286 involved hardware task switching that nobody ended up using. You're programming against forty years of backward compatibility, and every one of those layers is still there, still mandatory, still silently breaking things if you get it wrong.
The gap between "works in Ring 0" and "works in Ring 3" is enormous. A kernel that runs entirely in supervisor mode can be surprisingly simple. The moment you add user mode, you need: the TSS (so the CPU knows where the kernel stack is), Ring 3 GDT segments, trap gates for syscalls, a mechanism to build fake interrupt frames for the initial iret into user mode, and careful validation of every pointer that crosses the kernel boundary. Each of these is individually straightforward. Getting them all correct simultaneously is not.
Preemptive scheduling is simpler than it sounds. The concept (save state, pick next process, restore state) translates almost directly into code. The context switch is twelve instructions of assembly. The scheduler is a for loop. What makes it tricky is the interaction with everything else: the TSS must be updated, the interrupt must send EOI before switching, the process's kernel stack must be set up so that restoring registers and returning lands in the right place. The scheduler itself is trivial. The invariants it depends on are not.
Writing a network stack is an exercise in byte ordering. Ethernet is big-endian. x86 is little-endian. IP addresses, port numbers, checksums, packet lengths: every multi-byte field requires explicit conversion. Miss one htons() and your packets are valid-looking garbage. The RTL8139 driver, the ARP implementation, the IP checksum; each is maybe fifty lines. The debugging when a byte is swapped is hours.
The Numbers
JokelaOS in its current form:
| Component | Files | Approximate LOC |
|---|---|---|
| Boot (ASM) | 3 | ~120 |
| Kernel core | 16 | ~1,200 |
| Drivers | 2 | ~250 |
| Network stack | 5 | ~450 |
| Total | 26 | ~2,000 |
Two thousand lines for a kernel that boots, manages memory with paging, runs preemptive multitasking with Ring 3 isolation, handles interrupts, implements syscalls, has a working network stack, and provides an interactive shell. No line is borrowed from another project. Every byte is accounted for.
The entire thing builds in under a second and the binary is around 40 KB. make run goes from source to a running kernel in QEMU in about two seconds. This fast iteration cycle is what made the project possible; every subsystem was tested immediately after being written, and bugs were caught before they could compound.
What's Next
The point of JokelaOS was never to build a production operating system. The point was to understand what an operating system actually does: not in the abstract, not from a textbook diagram, but in the specific, concrete sense of "these bytes go into these ports in this order and then the hardware does this thing." Every subsystem in JokelaOS exists because I wanted to understand it, and the only way to truly understand a piece of systems software is to write it yourself.
The source code is on GitHub.