Over the past few weeks I've generated three technical handbooks using Claude Code with Opus 4.6 and the Claude Agent SDK. The Ballistics Engine Handbook, 641 pages across 66 chapters covering computational exterior ballistics. The Lattice Handbook, 868 pages across 84 chapters documenting an entire programming language. The Sampo CPU Handbook, 871 pages across 82 chapters walking through the design, programming, and hardware implementation of a 16-bit RISC CPU.
That's roughly 2,400 pages and 232 chapters of deeply technical content, generated from real codebases by AI agents that read actual source files before writing about them.
These aren't ChatGPT summaries. They aren't the kind of vaguely plausible prose you get from asking an LLM to "write a book about X." Each handbook was produced by a framework that launches 10-12 Claude agents in parallel, each assigned a Part of the book, each with access to the real project source code, each writing LaTeX chapters grounded in actual implementation. The result is documentation that references real functions, real CLI flags, real instruction encodings, because the agents read the code before writing about it.
Why Handbooks?
Developer documentation is chronically underwritten. Most projects ship with a README, maybe some auto-generated API docs, and a handful of examples. If you're lucky, there's a tutorial. The gap between "reference documentation" and "understanding how to actually use this thing" is enormous, and it's the gap where handbooks live.
A good handbook explains not just what the API surface looks like but why the design decisions were made, how the pieces fit together, what the edge cases are, and how to use the tool effectively in real-world scenarios. Writing one for a complex project is a multi-month effort. For a solo developer maintaining a project in their spare time, it's effectively impossible; the opportunity cost is too high.
AI changes the math. If you can point agents at source code and get a coherent, accurate, 600-page handbook, the cost drops from months to hours. The output isn't a finished book; it's a first draft that needs review, editing, and correction. But it's a dramatically better starting point than a blank page.
The Source-Aware Approach
What makes this different from asking a model to "write a book about ballistics" or "write a book about CPU design" is that the agents have access to the actual codebase.
Each agent runs with its working directory set to the real project: the ballistics-engine Rust crate, the Lattice C compiler, or the Sampo CPU's Verilog and assembly. The agents have Read, Glob, and Grep access. They can open source files, search for function signatures, trace data structures, and understand the actual implementation before writing about it.
The chapter definitions in the generation script include explicit source file references:
sourceReferences: ["src/atmosphere.rs", "src/drag.rs", "src/drag_model.rs"]
When an agent starts writing a chapter on atmosphere modeling, the prompt tells it: read src/atmosphere.rs first. The agent opens the file, sees the ICAO standard atmosphere implementation, finds the actual function signatures and constants, and writes a chapter grounded in what the code actually does, not what a language model thinks atmosphere modeling might look like.
For the Ballistics Engine Handbook, this means chapters that reference real Rust functions, real CLI flags from src/cli_api.rs, and real numerical methods from the solver. For the Sampo CPU Handbook, it means chapters that include actual Verilog module definitions, actual ISA encodings from the architecture spec, and actual assembler passes from the Rust toolchain. The agent reads ENCODING.md and writes about instruction formats using the real bit layouts, not invented ones.
This source-awareness is the difference between documentation that happens to sound plausible and documentation that is grounded in implementation. It doesn't eliminate hallucination (I'll get to that), but it dramatically reduces it.
The Parallel Agent Framework
The core of the system is a TypeScript file called generate.mts that orchestrates parallel Claude Agent SDK sessions. Each handbook has its own version, but the architecture is the same.
The book structure is defined as TypeScript data:
interface Chapter { number: number; title: string; filename: string; description: string; pages: number; sections: Section[]; sourceReferences: string[]; } interface Part { number: number; title: string; description: string; pageTarget: number; chapters: Chapter[]; }
Each Part contains its chapters, each chapter lists its sections, page target, and which source files the agent should read. The Ballistics Engine Handbook has 9 Parts. The Lattice Handbook has 11. The Sampo Handbook has 11 plus appendices.
When you run npx tsx generate.mts, every Part launches as a separate Claude agent simultaneously:
const promises = [ ...BOOK_STRUCTURE.map((part) => runPartAgent(part)), runAppendixAgent(), ]; const settled = await Promise.allSettled(promises);
For the Sampo Handbook, that's 12 agents running in parallel. Each one receives a detailed prompt containing:
- The full table of contents (so it knows what other Parts cover, for cross-reference awareness)
- Its specific chapters, sections, descriptions, and page targets
- Source file references to read before writing
- A style guide (more on this below)
- LaTeX formatting conventions, custom environments, and commands
Each agent calls the Claude Agent SDK's query() function with Opus 4.6, running in the source project's directory:
for await (const message of query({ prompt, options: { cwd: "/Users/alexjokela/projects/ballistics-engine", allowedTools: ["Read", "Glob", "Grep", "Write", "Bash"], permissionMode: "bypassPermissions", maxTurns: 30 + part.chapters.length * 8, model: "claude-opus-4-6", }, })) { ... }
The agents write LaTeX .tex chapter files to a chapters/ directory, which are \include{}'d by the main book.tex. Each agent logs its progress to a per-part log file. When all agents finish, the script reports results: duration, success/failure status, and file sizes for each generated chapter.
Promise.allSettled() is important here. If one Part fails (the agent hits a turn limit, encounters an error, or produces incomplete output), the other nine or ten agents keep running. You can rerun a single failed Part with --part=N without regenerating the entire book.
The parallelism is the key performance insight. A single agent writing all 82 chapters of the Sampo Handbook sequentially would take many hours. Twelve agents writing in parallel, each handling 7-8 chapters, complete the entire book in roughly 45 minutes to an hour of wall-clock time. The agents don't share state or coordinate; they work independently, which is what makes parallelism straightforward.
The Style Guide Problem

Each handbook has a distinct voice, defined in a CLAUDE.md file that the agent reads before starting:
The Ballistics Engine Handbook: "Technical, authoritative, and practical. Inspired by O'Reilly's Definitive Guide series." Use real cartridge data in every example. Show the physics. Include safety warnings for anything involving pressure or load data.
The Lattice Handbook: "Conversational, precise, and playful. Inspired by Why's (Poignant) Guide to Ruby and Eloquent Ruby." Use chemistry and materials science metaphors for the phase system: values are materials that can be fluid or crystallized, freezing is literally crystallization.
The Sampo CPU Handbook: "Technical, authoritative, and hands-on. Think of it as a lab notebook that became a textbook." Show both hex and binary for instruction encodings. Use real code from the project; never invent hypothetical assembly or Verilog.
Maintaining consistent voice across 10-12 agents writing simultaneously is a genuine challenge. Each agent reads the same style guide, but interpretation varies. What works: detailed, specific instructions with concrete examples of what to do and what not to do. All three guides include an explicit list of banned words ("simple," "easy," "trivial," "obviously," "just") because those words make struggling readers feel bad and they're the first thing an LLM reaches for when transitioning between concepts.
What doesn't work: vague instructions like "be conversational" or "keep it engaging." Every agent interprets those differently. The Lattice Handbook's metaphor system (where the phase-based type system is described using chemistry analogies) required explicit instructions: "Values are materials. Freezing is crystallization. Thawing is melting. Arenas are regions where crystals are stored." Without that specificity, some agents would use the metaphors and others wouldn't, and the book would feel like it had multiple authors, which, in a sense, it does.
The "no AI self-reference" rule is also critical. The style guide explicitly states: "Book content must read as if written entirely by the author, with no references to AI assistance." Without this, agents occasionally produce meta-commentary about their own generation process, which breaks immersion.
What Goes Wrong
An honest assessment of failure modes:
Hallucinated APIs. Despite source-awareness, agents sometimes invent function signatures, CLI flags, or configuration options that don't exist. This is the most dangerous failure mode because it reads authoritatively. The mitigation (explicit source file references) reduces but doesn't eliminate it. Every chapter needs a review pass where someone checks that the referenced functions and flags actually exist.
Uneven depth. Some chapters come out thin, hitting the minimum viable content but lacking the depth a handbook reader expects. Others balloon beyond their page target with redundant examples. Page targets in the chapter definitions help, but agents treat them as loose guidelines.
Cross-reference gaps. Agent writing Part III doesn't know exactly what Agent writing Part VIII said. Each agent gets the full table of contents for awareness, but not the actual content of other Parts. This means cross-references are sometimes vague ("as we'll see in Chapter 25") or occasionally contradictory. The LaTeX \cref{} system helps (agents insert labels and cross-references that at least compile correctly), but semantic consistency across Parts requires a human review pass.
LaTeX formatting inconsistencies. Different agents make different choices about when to use \begin{notebox} vs. \begin{tipbox}, how to format code listings, whether to put output inline or in a separate listing. The style guide constrains this, but the variation is noticeable.
The confident-but-wrong problem. AI writes with unwavering authority about implementation details it misread. An agent might open a Rust file, misinterpret a match arm, and write a paragraph confidently explaining behavior that the code doesn't actually produce. This is the hardest failure to catch because the prose sounds correct and references real source files; you have to actually trace the logic to find the error.
The regeneration workflow handles most of these: rerun a single Part with --part=N, review the output, iterate. A full regeneration of one Part takes about five minutes, fast enough to make iterative refinement practical.
Results and Numbers
Across the three handbooks:
| Ballistics Engine | Lattice | Sampo CPU | |
|---|---|---|---|
| Pages | 641 | 868 | 871 |
| Chapters | 66 | 84 | 82 |
| Parts | 9 + Appendices | 11 | 11 + Appendices |
| Parallel Agents | 10 | 11 | 12 |
| Source Language | Rust | C | Verilog/Rust/Assembly |
| Style | O'Reilly Guide | Why's Poignant | Lab Notebook |
The model for all three is Claude Opus 4.6. Total generation time per handbook is roughly 45-60 minutes wall-clock with parallel agents, compared to what would be 8+ hours running sequentially.
What This Costs
All of this work was done on a Claude Max subscription at \$200/month. At that tier, you get access to Opus 4.6 through Claude Code with what Anthropic describes as "significantly higher" usage limits than the \$20 Pro plan. How much higher? That's where things get vague.
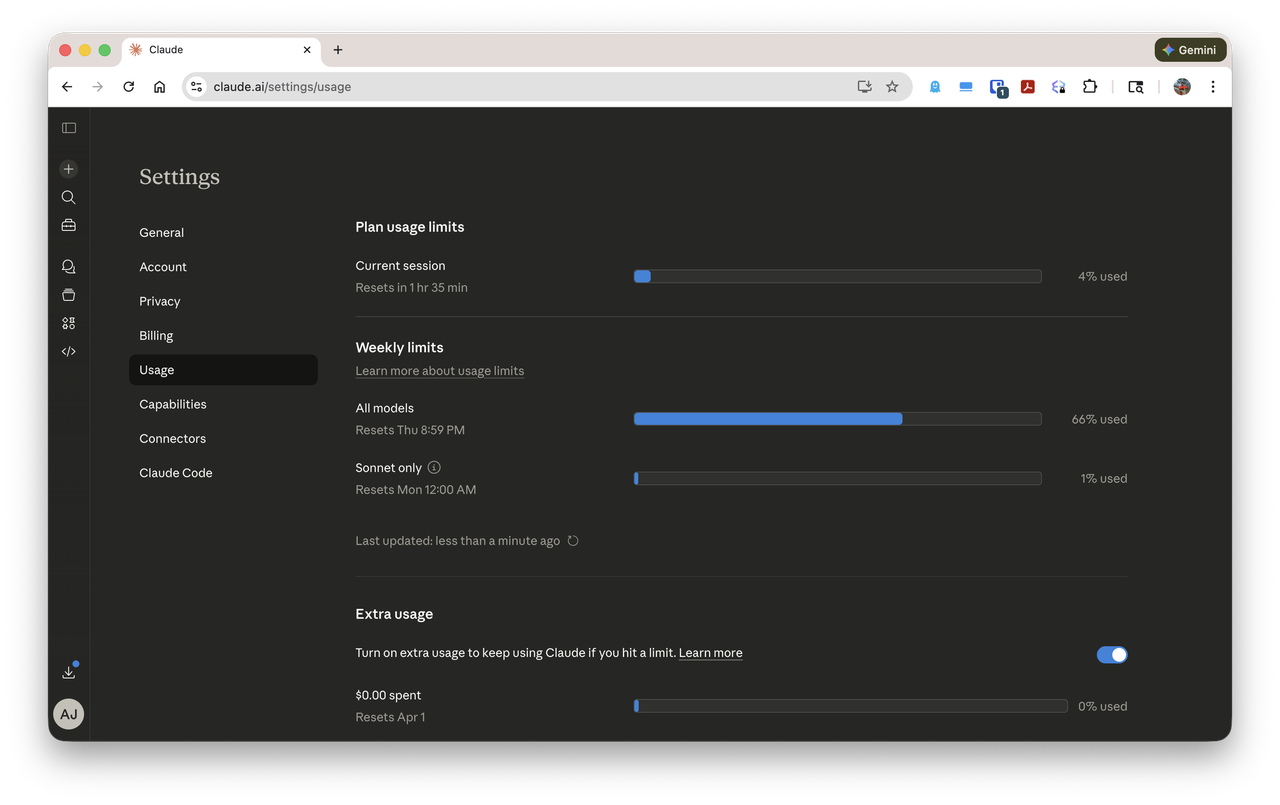
Anthropic doesn't publish concrete token limits or rate caps for Max. The pricing page says you get "9x more usage" than Pro, but 9x of what? The Pro plan's limits are themselves unstated. You get a usage meter in the interface that fills up and eventually throttles you, but there's no documentation of what the meter measures, how it maps to tokens, or what the actual ceiling is. When you hit the limit, you're told to wait or upgrade. The \$100/month tier exists between Pro and Max, and Anthropic is equally vague about how it differs from either.
In practice, the Max subscription was sufficient to generate all three handbooks (2,400 pages of content produced by dozens of parallel agent sessions running Opus 4.6) within a single billing cycle, without hitting much throttling that would have blocked the work. Whether that's representative of the limit or I happened to stay under it, I genuinely don't know. Anthropic's refusal to publish concrete limits makes it impossible to do the math in advance. You can't calculate cost-per-page or tokens-per-dollar because the denominator is secret.
This is a strange posture for a company selling a product. The \$200/month price point positions Max as a professional tool, something you'd expense to a business or justify as a productivity investment. Professional tools come with specs. You know how many build minutes your CI plan includes. You know how many API calls your database tier supports. You know how many seats your Slack plan covers. Anthropic is asking for \$200/month and answering the question "what do I get for that?" with essentially "a lot, trust us."
For what it's worth, the alternative would have been the API, where pricing is transparent: Opus 4.6 runs roughly \$15 per million input tokens and \$75 per million output tokens. Back-of-envelope math suggests that generating a single 800-page handbook through the API (with all the source file reading, prompt construction, and chapter output) would consume something in the range of several hundred dollars of tokens. Three handbooks would plausibly run \$500-1,000+ through direct API billing. If that estimate is in the right ballpark, the Max subscription is a genuine bargain for this kind of heavy-generation workload, but you just have to take it on faith because Anthropic won't show you the numbers.
For comparison against the alternative: a professional technical writer producing this volume of deeply technical content (requiring them to understand exterior ballistics physics, or compiler internals, or CPU microarchitecture) would represent months of full-time work at rates that would make the API costs look trivial. The AI-generated output is a first draft, not a finished product. But it's a first draft that covers the full scope, references real source code, and provides a structure that would take weeks to produce manually.
What This Means for Documentation
This connects to a theme I've been writing about in the Jevons Paradox series: documentation is a classic example of latent demand suppressed by cost.
Most open-source projects have mediocre documentation because good documentation is expensive to produce. A solo maintainer choosing between implementing features and writing a 600-page handbook will choose features every time. The handbook doesn't get written, not because it wouldn't be valuable, but because the cost of producing it exceeds the maintainer's available time.
If handbook generation becomes cheap enough, every serious project gets one. The total volume of technical documentation doesn't decrease; it explodes. And the human role shifts from production to curation. The expensive work isn't writing 600 pages anymore. It's defining the structure: deciding what the book should cover, in what order, at what depth. It's reviewing the output for accuracy: catching hallucinated APIs, verifying that code examples actually run, ensuring cross-references are coherent. It's editing for voice: making sure the playful tone of the Lattice Handbook doesn't lapse into the authoritative register of the Ballistics Handbook.
This is Jevons in miniature. Cheaper documentation doesn't mean less documentation work. It means more documentation exists, and humans focus on the higher-judgment parts: structure, accuracy, and editorial voice.
The Framework Is the Product
The generate.mts pattern is reusable. The same architecture (define a book structure in TypeScript, launch parallel agents with source code access, collect LaTeX output) applies to any project with a codebase and a desired handbook.
The bottleneck isn't the AI's ability to write. It's the human's ability to define what the handbook should contain and whether the output is correct. Defining the structure for the Sampo Handbook (11 Parts, 82 chapters, hundreds of sections, source file references for each) took longer than running the generation. Reviewing and correcting the output takes longer than generating it.
That bottleneck is itself a Jevons observation. When the cost of producing prose drops to near zero, the scarce input becomes human judgment about what the prose should say and whether it's right. The generation is the cheap part. The thinking is the expensive part. As it always has been.